En entornos donde cada segundo cuenta, la capacidad de gestionar, visualizar y analizar información geográfica de forma precisa es un factor determinante para el éxito operativo. Desde la Suite gvSIG, estamos impulsando una solución integral diseñada para modernizar las Infraestructuras de Datos Espaciales (IDE) y optimizar los procesos de respuesta ante emergencias y asistencia ciudadana.
Un ecosistema de trabajo completo
Nuestra propuesta tecnológica se basa en la integración de tres pilares fundamentales que cubren todo el ciclo de vida del dato espacial:
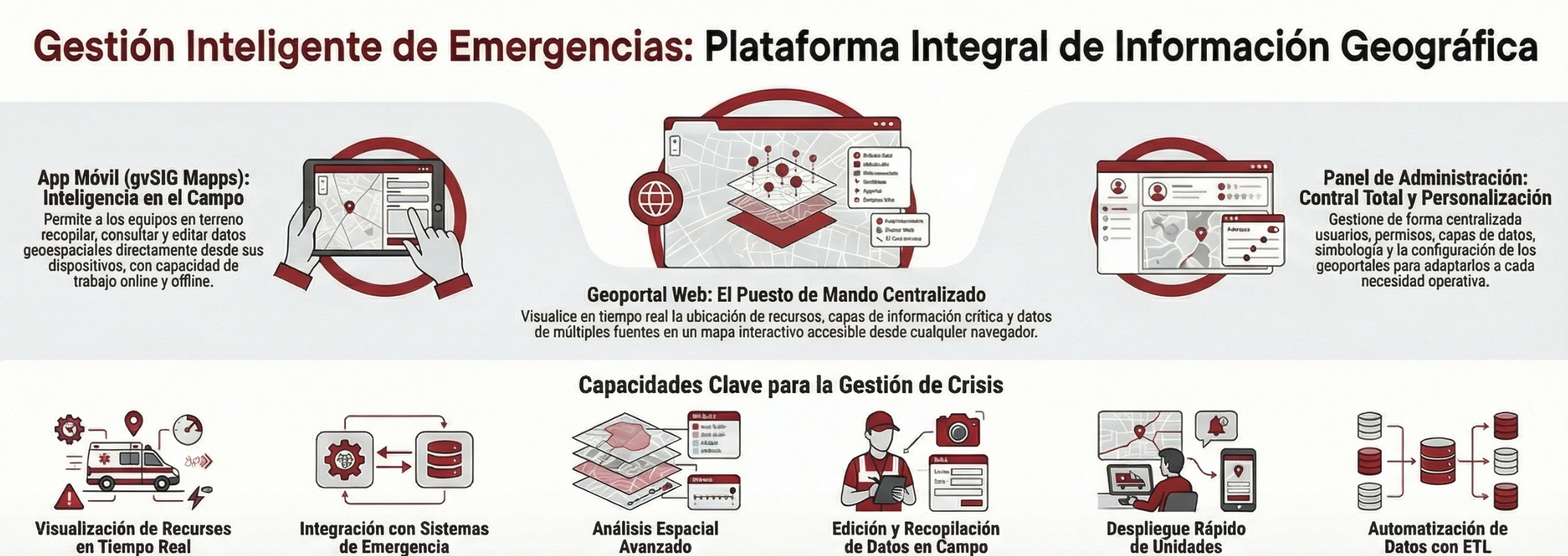
- gvSIG Online (El núcleo de la IDE): Una plataforma robusta que permite catalogar, localizar y compartir información mediante geoportales web accesibles. Basada en estándares OGC y en un modelo interoperable, facilita la integración de cartografía oficial y servicios externos como OpenStreetMap (OSM).
- gvSIG Mapps (Captura en tiempo real): La herramienta móvil para la toma de datos en campo. Permite a los equipos operativos actualizar información geográfica y alfanumérica, incluso en modo offline, sincronizando los cambios automáticamente al recuperar la conexión.
- gvSIG Desktop (Edición avanzada): Orientado a usuarios expertos, este componente actúa como un editor avanzado de datos espaciales, permitiendo realizar tareas complejas de manipulación cartográfica y análisis de gabinete con máxima precisión.
Funcionalidades diseñadas para la acción
La plataforma no solo visualiza datos, sino que los convierte en inteligencia operativa a través de herramientas específicas:
- Gestión de recursos en tiempo real: Integración con sistemas de comunicaciones para monitorizar el estado operativo de los recursos (en ruta, llegada al servicio) mediante iconos dinámicos que se actualizan según la intervención.
- Notificaciones Push y Waypoints: Capacidad de enviar puntos de interés específicos (como hidrantes o ubicaciones de riesgo) directamente a los dispositivos de los equipos de intervención.
- Análisis Temporal (4D): Herramientas para consultar la evolución de fenómenos geoespaciales mediante filtros de fechas, facilitando el análisis histórico y la evaluación de tendencias.
- Motor ETL Avanzado: Una interfaz gráfica intuitiva que permite automatizar la transformación e integración de múltiples fuentes de datos sin necesidad de programación adicional.
Hacia el Gemelo Digital: IA y Dashboards
El futuro de la geomática aplicada a emergencias pasa por la capacidad de síntesis. Mediante nuestro módulo de GeoCopilot, integramos la Inteligencia Artificial en gvSIG Online para que los usuarios realicen consultas complejas sobre los datos utilizando lenguaje natural. Esto se complementa con la generación de cuadros de mando (dashboards) interactivos que muestran indicadores clave (KPIs) para una toma de decisiones ejecutiva ágil y visual.
Sostenibilidad y Libertad Tecnológica
Nuestra apuesta por el software libre garantiza que las organizaciones mantengan la soberanía sobre sus datos, evitando dependencias de licencias propietarias y asegurando una solución escalable, adaptable e infinitamente integrable.